With the increase in internet use for the last decade, the number of data stored has also increased. This data can have many uses, and one of them is to predict consumer behaviour.
More specifically, in our case the data recorded come from purchases in retail stores. This data is accumulated, but in earlier times it was not possible to process this data.
During the data mining process, the data is stored electronically and their categorization is automated by a computer. This automates the process, and we are now called upon to find correlations and patterns within this data.
By mining data, scientists and analysts try to extract knowledge from already recorded data. But there are several more specific definitions that give clearer boundaries to what we call data mining. In fact, the largest collection of data ever made is through electronic devices, and in data mining we use computers to process the vast amount of data that has accumulated.
Data Types
As a general technology, data mining can be applied to any type of data, as long as the data makes sense for a target application. The most basic data formats for mining applications are database data, data warehouse data, and transaction data.
Database Data
A database system, also called a database management system (DBMS), consists of a collection of interconnected data, known as a database, and a set of software programs for managing and accessing data. Software programs provide mechanisms for defining database structures and data storage. These tools are used to identify and manage synchronous, shared, or distributed data. There are also system defence tools used to ensure the consistency and security of information stored primarily against unauthorized access attempts.
Data Warehouse
A data warehouse is a repository of information collected from multiple sources, stored under a unified system, and usually stored on a single website. Data warehouses are built through a process of data cleansing, data integration, data transformation, data loading and periodic data renewal.
Other Data Types
In addition to relational database data, data warehouse data, and transaction data, there are many other types of data that have flexible forms and structures, and rather different meanings. These types of data can be observed in many applications: time or sequence data (e.g. historical records, stock market data and time series and biological sequence data), data streams (e.g. data video and sensor monitoring (e.g. design of buildings, system components or integrated circuits), multimedia data (including text, image, video and audio data), spatial data, network data (e.g. data from social networks and information networks), as well as many other types of data that can be found on the World Wide Web. These applications create new challenges, such as manipulating data that carries specific structures (e.g., sequences, trees, graphs, and networks) and specific semantics (such as order, image, audio and video content, and connectivity) (Grabmeier & Rudolph, 2002).
Data Mining Tools

Data mining tools are programs that can process data with artificial intelligence and machine learning techniques. Data mining tools are programs that can process data using artificial intelligence and machine learning techniques. As we can see from the image above, some of them are the programming language Python, R, MATLAB, Orange, Qlik and many others that allow us to apply data mining techniques usually with visualization.
Data Mining Techniques
Data mining techniques includes:
- Anomaly detection: The identification of unusual data entries, which may be of some interest or error in the data requiring further investigation. An example is the follow diagram.
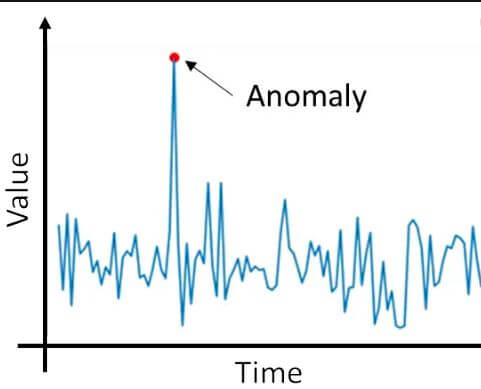
- Classification-Categorization: It is the process of generalizing known structures for its application on new data. For example, an e-mail program might try to label an e-mail as legitimate or spam.

- Clustering: This is the process of discovering groups and structures in data that are “similar” in some way, without using known structures in the data.
- Correlation analysis (Interdependence model): Searches for relationships between variables. For example, a supermarket may collect data on its customers’ shopping habits. Using them correlation rules, can calculate which products are usually purchased together and use this information for purchasing purposes for the benefit of its customers and itself.
- Regression: The main purpose here is to predict the value of a variable by studying the values it had in the past. In particular, regression using a numerical database develops a mathematical relation that fits that data. This mathematical relationship is then used to predict future behaviour by applying new arithmetic data to it. The main limitation of this technique is that it applies well only to continuous quantitative data.


